c++을 4년간 하고 몇년 동안 쓰지 않아 기억이 잘 안나게 되었습니다
하지만 코딩 테스트를 준비해야하기 떄문에 기초부터 다시 쌓는다는 마음으로 공부한 코드들 기록해나가려고 합니다.
목표 : 매일 꾸준히 포스팅 1개라도 하기!
6개월 이상 길게 보되, 기록은 매일 하기! 댓글 주시면 넘 감사합니다!
#include <iostream>
using namespace std;
int main()
{
for (int i = 0; i < 38; i++)
{
cout << "#";
}
cout << endl;
cout << "# C++ 기초 부터 백준 골드까지!#\n";
for (int i = 0; i < 38; i++)
{
cout << "#";
}
cout << endl;
return 0;
}
#include <iostream>
using namespace std;
int main()
{
//3개의 변수 정리 (정의 되지 않는 변수는 사용이 어렵다)
int a;
int b;
int c;
//각 변수에 100, 200, 300 값을 넣는다
a = 100;
b = 200;
c = 300;
cout << a << ", " << b << ", " << c << "\n";
return 0;
}
C++ 변수 규칙
1. 중복된 이름 변수 사용 불가
2. 변수 이름에는 알파벳, 숫자 _ (언더스코어)만 가능
3. 숫자는 변수 이름 첫번째 위치 불가
4. 변수 이름의 알파벳은 대소문자 구분
5. 키워드는 변수 이름 사용 불가
변수 타입
unsigned 는 양수만 담을 수 있다. 음수 보관할 수 없는 대신에 더 큰 양수를 보관할 수 있다.
정수는 길이, 실수는 정밀도
1비트 = 0과 1, 2가지 상태
8비트는 1바이트
16비트는 2바이트
1MB(메가바이트)는 1024KB(킬로바이트)
1KB(킬로바이트)는 1024바이트
1024바이트는 1024X8 비트
결국 변수가 얼마나 큰 값을 보관할 수 있는지는 변수가 몇 개의 바이트로 이루어져있느냐!
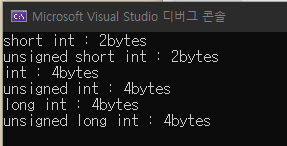
sizeof(short int) => 2byte -> 16비트 => 2^16승가지 표현 가능.
#include <iostream>
using namespace std;
int main()
{
cout << "short int : " << sizeof(short int) << "bytes \n";
cout << "unsigned short int : " << sizeof(unsigned short int) << "bytes \n";
cout << "int : " << sizeof(int) << "bytes \n";
cout << "unsigned int : " << sizeof(unsigned int) << "bytes \n";
cout << "long int : " << sizeof(long int) << "bytes \n";
cout << "unsigned long int : " << sizeof(unsigned long int) << "bytes \n";
}
여기서 찾아본 점
int와 long int의 차이
int의 크기는 CPU 성능에 따라 바뀌기 때문에
초기 16비트 CPU 사용 당시에는 int가 2바이트, long이 4바이트로 이용되었다.
하지만 32비트, 64비트 CPU가 개발되면서 오히려 int가 long보다 더 클 수도 있는 모순이 생겼다.
이를 보완하기 위해 32비트 이상의 아키텍처를 사용할 경우 4바이트로 고정하기로 했다.출처: https://asdfmelody.tistory.com/89 [고슴도치의 IT여행:티스토리]
32비트 컴퓨터는 한번에 처리할 수 있는 크기가 32비트
signed는 음수 상태 표시하기에 절반은 양수, 절반은 음수 표현
#include <iostream>
using namespace std;
int main()
{
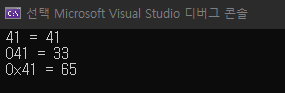
//각각 10,8,16진법
int decimal = 41;
int octal = 041;
int hexadecimal = 0x41;
//출력
cout << " 41 = " << decimal << endl;
cout << " 041 = " << octal << endl;
cout << " 0x41 = " << hexadecimal << endl;
}
실수 타입 (부동 소수점 타입)
C++에서는 실수 뒤에 f가 붙어 있지 않으면 double 타입에 상응하는 실수값이라 생각함.
부동 소수점 타입은 변수의 일정 공간에는 유효자리를 저장하고 나머지 공간에는 지수를 저장하고 있다.
1.2345 X 10^-4 => 부동소수점 저장 방식
문자타입
char : 표현할 수 있는 문자 수 제한 (아스키코드)
wchar_t : 세계 각국의 문자와 기호 표현 가능 (유니코드)
char형은 보통 1바이트 크기를 가지며 2의8승 비트 상태를 갖는다. 그래서 256개의 상태 각각의 문자를 의미한다고 본다char은 단순히 작은 크기의 정수 타입
#include <iostream>
using namespace std;
int main()
{
//'A'의 아스키코드 값 확인
int a = 'A';
cout << a << "\n";
//65를 문자로 표현하면
char b = 65;
cout << b << "\n";
return 0;
}
형변환시 발생할 수 있는 문제
double -> float : float 타입이 보관하기에는 정밀도가 높은 실수를 대입하고 있다 형변환 시에 근사값으로 변환된다. 근사값으로의 변환도 불가능한 경우에는 이상한 값으로 변질될 수 있다
float -> short : float 변수의 정수 부분이 short변수가 담을 수 있는 크기보다 큰 경우 이상한 값으로 바뀔 수 있다.
int -> float : 기본적으로 실수 타입은 정수 타입보다 큰 수를 보관할 수 있지만, 내부 구조상 정밀도를 잃어버릴 수 있다.
명시적 형변환시 임시변수가 수반된다.
추후 이러한 임시 객체 때문에 발생하는 문제점이나 성능 저하에 대해 논할 수 있다